



You’re probably already familiar with the idea of offline web apps, web apps that can continue to work in the face of intermittent network connectivity. This concept has been around for a while, and various technologies have been developed along the way to achieve offline web apps, (Google) Gears, and Appcache for example, but none of these addressed the offline challenge quite as well as service workers.
What is a service worker?
Service workers provide a way for webpages to run scripts in the background even when the page is not open. A service worker can act as a proxy to a web page, intercepting requests and controlling responses, and this makes them well suited to dealing with many exciting web features, such as offline capabilities, background syncing, and push notifications. Features like these have traditionally given native apps an edge over web apps, but with service workers, all kinds of previously impossible things are now possible on the web. This means service workers are a very big deal!
What are offline web apps?
The term offline web app can mean different things to different people. A good description of what is meant by an offline web app is given in this article: What’s offline and why should I care? Sometimes called online-offline, what we’re really talking about in this article is a class of web app that can function, at least to some useful degree, with an intermittent network connection.
Why are offline web apps desirable?
Two main reason are availability and performance:
- Availability A web app can still work without a network connection, thus making it available
- Performance Because a web app makes content offline, by caching requests and responses as we’ll see later, this means that it can be much quicker to retrieve and present content to the user, often without having to make a network request
Offline web app use cases
Now with some idea of what an offline webapp is, we can list a few use cases:
- Simple case: caching to improve performance and availability
- Collaborative document writing
- Communcation: for example composing email offline, which sends when online again
A list of interesting offline projects and use cases is given on the W3C Web and Mobile (WebMob) Interest Group’s GitHub page.
However, there is no doubt that to endow a web app with offline capabilities is more complex than to build a web app without. There are cache policies to consider, issues around stale content, when to update, and how to notify users that there is newer content, all of which must be considered so that the user experience is not accidentally adversely affected. For example, updating a piece of content while a user is reading it might be jarring if the user was not expecting it. As pointed out by Michael Mahemoff, you should be able to justify the complexity of making your web app available offline.
In this article we’ll show how to add basic offline capabilities to a webapp, which sort of corresponds with the offline magazine app suggestion on the WebMob Service Workers Demo page given above, although what we develop here will be more of a proof of concept that a full blown offline solution.
Why not just use the browser cache?
Sure, browsers cache stuff all the time. The advantages here are in persistence and control. Browser caches are easily overwritten while an application cache is more persistent. Badly configured servers often force the client to refetch things unecessarily, for example hosting providers you don’t have control over. Service workers, with a full caching API, allow the client full control, and can make smarter decisions about what and when to cache. Many of us have experienced the case where we get on a plane with a page loaded in our browser, only to find that either a browser setting or cache header forces a reload attempt when you then go to read the page, a reload that has no hope of succeeding, and your page is gone.
Getting started with service workers
Let’s get the service worker basics out of the way.
HTTPS
Firstly, HTTPS is required for service workers. Since service workers control webpages and how they respond to a client, HTTPS is needed to needed to prevent hijacking.
Registering a service worker
To register a service worker, you need to include a reference to the service worker JavaScript file in your web page. You should check for service worker support first:
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/sw.js').then(function() {
// Success
}).catch(function() {
// Fail :(
});
}
Scope refers to the pages the service worker can control. In the above, the service worker can control any under the root and its subdirectories.
Lifecycle
The lifecyle of a service worker is a little bit more complex than this, but the two main events we are interested in are
- Installing – perform some tasks at install time to prepare your service worker
- Activation – perform some tasks at activation time
Implicit in the above is that a service worker can be installed but not active. On first page-load the service worker will be installed, but it won’t be until the next page request that it actually takes control of the page. This default behaviour can be overridden, and a service worker can take control of a page immediately by making calls to the skipWaiting() and clients.claim() methods.
Service workers can be stopped and restarted as they are needed. This means that global variables don’t exist across restarts. If you need to preserve state then you should use IndexedDB, which is available in service workers.
Fetching and caching
Two key components of getting service workers to build offline apps are the cache, and fetch APIs. The cache allows us to store requests and responses, while fetch allows us the intercept requests, and serve up cached responses. Using cache and fetch together enables us to concoct all kinds of interesting offline scenarios. See Jake Archibald’s Offline Cookbook for an excellent hands-on review of various caching policies you might use.
Service Worker Cache API
Service workers bring a new cache API to the table. Let’s have a quick look at this. With the CacheStorage object we can open (and name), and delete individual caches. With individual caches, typical operations are to add and remove items. So, let’s open a cache and and store some pages.
// Add the addAll method
importScripts('sw-cache-addall.js');
// A list of paths to cache
var paths = [
'/',
'/css/main.css',
'/js/main.js',
'/about.htm'
];
// Open the cache (and name it)
caches.open('offline-v1').then(function(cache) {
return cache.addAll(paths);
})
Fetch requests with service workers
By listening for fetch events from web pages under its control, a service worker can intercept, manipulate and respond to requests for those pages. For instance, the service worker can try to pull content from its cache, and if that fails then go to the network for the original request:
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request).then(function(response) {
return response || fetch(event.request);
})
);
});
Communicating with Service Workers: postMessage
Service workers control pages, but they don’t have access to the DOM. However, service workers and web pages can communicate by sending messages to each other via the postMessage() method. To send a message from webpage to service worker you could use:
navigator.serviceWorker.controller.postMessage({'command': 'say-hello!'})
Note that the structure and content of the message is entirely up to you.
And to send a message from service worker to a page that it controls, you could use:
client.postMessage({'message':'hello!'});
You’ll need to get a reference to the client page, as a service worker might control multiple pages.
To receive a message in either page or service worker, we need to set up a listener for the message event. In a webpage we set it up as:
navigator.serviceWorker.addEventListener('message', function(event) {
//do something with the message event.data
})
In the service worker we set it up with:
self.addEventListener('message', function(event) {
//do something with the message event.data
})
And for completeness, to send a message to a service worker from a page, and to receive a response from the service worker, then you must also provide a message channel in the original message that the service worker can use to reply via. You can see an example of this in this Service Worker two way postMessage example article.
Additionally, since a service worker intercepts requests, it’s also possible to communicate with the service worker via HTTP request, with the service worker responding perhaps with a JSON response.
Building offline web apps with server workers
After that quick introduction to service workers, you should now have a rough idea what they are, and how to use them, and you’re hopefully convinced of the benefits of offline-capable web apps; now it’s time to build an offline web app with service workers.
As a working demo, we’ll add some offline capabilities to mobiForge so that it will have opt-in offline-reading capabilities. It will work as follows:
- User opts-in by via checkbox
- Web page sends message to service worker
- Service worker fetches recent content and caches it
- For each subsequent request, service worker checks cache first, and falls back to network if content is not found. If network is unavailable and page is not available offline, a new ‘not available offline’ page is displayed.
Service worker offline reading demo
The impatient reader can click through to the demo now; after opting in, kill the network on your device, and follow the link to the offline content.
Implementing offline reading with service workers
First we register the service worker on our web page:
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/sw.js').then(function() {
console.log('Service worker registered');
}).catch(function() {
console.log('Service worker registration failed');
});
}
else {
console.log('Service worker not supported');
}
We’ll want to cache some static resources when the service worker is installed, but we’ll come to that later; let’s stick with the web page code for now.
Next, we’ll build the user interface. It’s just a simple checkbox for an all-or-nothing opt-in. A better interface might allow the user to specify exactly what content he or she wanted to make available offline, by topic or category, or by author, for example.
Because a service worker can be terminated and restarted as needed, you can’t rely on it to store state across restarts. If you need persistent data, then you can use IndexedDB. Since we only want to store a simple boolean in this example opt-in to keep things simple we’ll just use localStorage to store this state, but in general if you have state information to store it would probably be better to use IndexedDB.
<div id="go-offline"></div>
And the JavaScript:
var optedIn = false;
window.onload = function() {
if('serviceWorker' in navigator) {
document.getElementById('go-offline').innerHTML = '<h4>mobiForge offline reading</h4><input type="checkbox" name="go-offline" id="go-offline-status" value="false" /><label for="go-offline-status">Make recent articles available for offline reading</label><div id="off-line-msg"></div>';
checkOptedIn();
document.getElementById("go-offline-status").addEventListener('click', function(){
console.log('start/stop fetching');
optInOut();
});
}
else document.getElementById('go-offline').innerHTML = 'ServiceWorker not supported :-(';
};
Note that we need to check the opt-in status with checkOptedIn. This just checks the value of the localStorage item with the following code, and sets the checkbox appropriately:
function checkOptedIn() {
console.log('checking opted in...')
if(!!localStorage.getItem('offlineoptin')) {
optedIn = true;
document.getElementById("go-offline-status").checked = true;
console.log('opted in');
return;
}
else console.log('not opted in');
}
Note also that we added a click handler for the check box, which call optInOut. Recall from earlier that pages and service workers can communicate by posting messages to each other. To allow a user to opt-in to offline, we’ll provide a checkbox which, when checked, will post a message to the service worker to make the most recent content available offline. We could also have a Make this article available offline associated with each article, in addition to, or instead of our Make all recent content available offline checkbox. This is left as an exercise for the reader.
function optInOut() {
if(!optedIn) {
optedIn = true;
localStorage.setItem('offlineoptin', '1');
navigator.serviceWorker.controller.postMessage({'command': 'offline-opt-in'});
}
else {
optedIn = false;
localStorage.removeItem('offlineoptin');
navigator.serviceWorker.controller.postMessage({'command': 'offline-opt-out'});
}
}
So that’s the interface out of the way, and communication is set up with the service worker. Let’s look at the service worker code.
Service worker implementation
The service worker needs to cache some basic static resources. When the user opts in, it should also cache the most recent content. It will pull this from the home page of the site which contains a stream of the latest posts. We’ll cache this page, plus each of the latest posts, and their associated assets.
We cache some basic static resources, such as images, scripts, and css that will be needed just to display every page. These resources are cached during the install event that was mentioned earlier; waitUntil ensures that the pages are cached before installation is completed:
// Add the missing addAll functionality
importScripts('sw-cache-addall.js');
// A list of paths to cache
var paths = [
'/',
'/css/main.css',
'/js/main.js',
'/img/logo.png',
'/about.htm'
];
self.addEventListener('install', function(event) {
event.waitUntil(
caches.open('offline-v1')
.then(function(cache) {
return cache.addAll(paths);
})
);
event.waitUntil(self.skipWaiting());
});
Next, we’ll listen out for messages from the web page, using the message event. We saw how to do this earlier:
self.addEventListener('message', function(event) {
//do something with the message event.data
})
To make the recent content available offline, we’ll fetch and cache the home page, as well as each of the recent articles listed on that page. We’ll scrape the HTML to get these links. This is a bit ugly; ideally, instead of scraping, it would be better to have an API that we could simply query for content.
We can pull out the links we need with a regular expression. Because we’re in control of the site, we don’t need to worry that it will be brittle.
For each URL we cache, we’ll want to cache its image assets, or it will look broken when served from cache, so we must take a look at the response, and also add any images included in the content to the cache. We perform this in a function fetchAndCache:
function fetchAndCache(url, cache) {
return fetch(url).then(function (response) {
if (response.status < 400) {
console.log('got '+url);
cache.put(url, response.clone());
}
return response.text();
}).then(function(text) {
var pattern = /img src=(?:'|")/((?:files|img)/[^'"]+)"/g;
var assets = getMatches(text, pattern, 1);
return cache.addAll(assets);
})
}
This code is outlined:
self.addEventListener('message', function(event) {
console.log('SW got message:'+event.data.command);
switch (event.data.command) {
case 'offline-opt-in':
// Cache homepage, and parse the top links from it
caches.open('static-v1').then(function(cache) {
fetch('/').then(function(response) {
fetchAndCache('/', cache);
return response.text();
})
.then(function(text) {
var pattern = /a href="([^'"]+)" class="item-title"/g;
var urls = getMatches(text, pattern, 1);
console.log('caching: ' + urls);
for(var i=0;i<urls.length;i++) {
console.log('fetching '+urls[i]);
fetchAndCache(urls[i], cache);
}
})
});
break;
}
});
Another helper function is used help pull out page and image URLs:
//helper
function getMatches(string, regex, index) {
index || (index = 1); // default to the first capturing group
var matches = [];
var match;
while (match = regex.exec(string)) {
matches.push(match[index]);
}
return matches;
}
Now it’s time to start intercepting requests. We saw how to do this earlier, by listening out for the fetch event. We need to think a bit about our caching policy at this point. For this example, we’ll keep it super simple: for the home page, we’ll implement network, then cache, then fallback. For all other pages, we’ll implement cache, then network, then fallback. The reasoning is: the home page is likely to change more often than article content. So, we don’t want the user to miss any new content when there is an network connection available. For the articles, we go straight to cache. A better solution would be to implement cache, then network and notify the user if there is newer content. But we’ll keep it simple here—this is more a proof of concept than a full-fledged offline solution.
self.addEventListener('fetch', function(event) {
var requestURL = new URL(event.request.url);
// Network, then cache, then fallback for home page
if(requestURL=='/') {
event.respondWith(
fetch(event.request).then(function() {
return caches.match(event.request);
}).catch(function() {
return caches.match('/page/content-not-available-offline');
})
);
}
// Cache, then network, then fallback for other urls
event.respondWith(
caches.match(event.request).then(function(response) {
return response || fetch(event.request);
}).catch(function() {
return caches.match('/page/content-not-available-offline');
})
);
});
And that about wraps it up. Note that this implementation is not perfect; it’s a partial offline solution retro-fitted onto an existing website. It required a little ugly scraping of links from the homepage. If we were building this from the ground up, it would be worth considering to implement a simple content API that we could query for content without HTML page template, and which we could query for new or updated content. We could also do a better job of ensuring necessary scripts and other assets are available offline, and we could also consider hiding functionality that is not available offline, such as the social sharing buttons. But despite these shortcomings, it still serves as a relatively accessible proof of concept of the power of service workers and in this case, their ability to build compelling offline experiences.
Caching patterns
Many applications may have unique caching requirements. Should you go to cache first, network first, or both at the same time? We chose a fairly simple approach for this example.Jake Archibald lists several useful patterns in his offline cookbook article. Every application will have its own needs, so choose, or develop, a caching solution that’s appropriate for your application.
Debugging
Two all important URLs for debugging service workers are
- chrome://inspect/#service-workers
- chrome://serviceworker-internals/
You can also view what caches have been opened, and what URLs are currently cached in them.
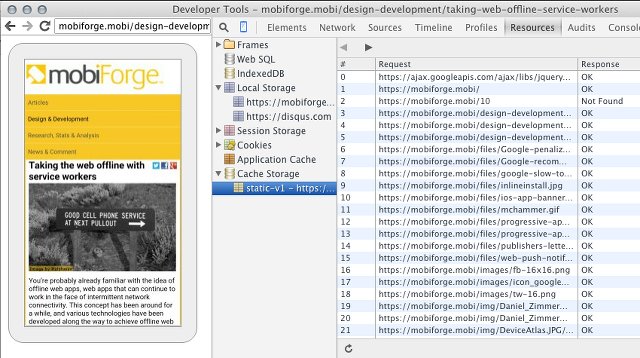
Remote debugging device, showing cache contents
You can also view registered service workers right from the Chrome Developer Tools. However, sometimes the service worker information pane disappears from Chrome developer tools altogether—be prepared to shut down Chrome and restart to bring it back!
Updating service workers
When you’re developing, you might run into trouble with the page loading the old service worker code. The trick here is that a reload won’t necessarily load the new service worker. Instead, close the current tab altogether, and then load the page again.
It can also be useful to unregister the registered service worker in the Developer Tools before reloading. And remember, unless you’re using skipWaiting()/clients.claim() your sevice worker won’t take control until the next time the page is loaded.
Read more about updating service workers here: Updating service workers.
Browser support and usage in the wild
While service workers aren’t universally supported yet, most of the main browsers are either working on bringing support, or have it on a roadmap. The notable exception is Safari.
Jake Archibald’s Is ServiceWorker Ready? page gives a very detailed run down of the level of support in the main browsers. A quick summary would be that right now there are usable implementations in Chrome, Firefox, and Opera; Microsoft’s Edge browser is likely to build support soon, but there are no signs right now that Apple will bring service worker support to Safari any time soon.

Service Worker browser support (adapted fromIs ServiceWorker Ready?)
Despite only partial support, service workers are popping up in websites everywhere. Just take a look at chrome://serviceworker-internals/ and you might be surprised to see the number of service workers listed from various sites that you’ve recently visited. With well planned usage, a site can function without service workers where it’s not supported, but will benefit from all that service workers have to offer where it is!
Links and credits
- http://www.w3.org/TR/service-workers/
- https://github.com/slightlyoff/ServiceWorker/blob/master/explainer.md
- https://jakearchibald.com/2014/service-worker-first-draft/
- https://developer.mozilla.org/en-US/docs/Web/API/Service_Worker_API/Using_Service_Workers
- https://jakearchibald.com/2014/offline-cookbook/
Once again, documentation by Matt Gaunt and Jake Archibald at Google has been indispensable!




Leave a Reply