



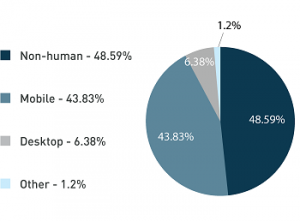
As we discovered in a 2016 DeviceAtlas Mobile Web Intelligence Report, up to 50% of all website traffic can be attributed to bots, dark traffic, spammy referrals and all sorts of ne’er-do-well actors.
Removing these sources from your reporting suite not only gives you a more accurate picture of where genuine traffic is coming from, but can help you plan ahead and put your spend where it works best for you. Muddying the waters can lead to incorrect assumptions and guesses, costing you money.
But what if you want to remove useless traffic not only from your reports, but from your overall web experience too? Is it possible to stop bots at the door, so they don’t appear in your reports and don’t even get to see your content? This can reduce infrastructure costs, bandwidth etc.
Let’s first examine where bots came from, why they were created, and why we’re now inundated with fake traffic, ad-fraud and click-spam as a result.
The evolution of bots
Bots, in the web-sense at least, are described as a “software application that performs automated tasks by running scripts over the internet”.
We use them every single day, unconsciously interacting with an armada of automated tasks in almost every interaction online.
They’ve been around as long as the web, and their building blocks long before. Today’s web-bots owe their existence to the groundwork laid by the likes of Babbage, Bertrand Russell and Alan Turing. The idea of creating a mechanical device to process information in an intelligent way has been the holy grail for mathematicians, engineers and lateral thinkers since Aristotle.
Today, the most common varieties of bad-bots we’ll encounter on the web exist to serve one of the following aims:
- Spambots that harvest email addresses from contact or guestbook pages
- Downloader programs that suck bandwidth by downloading entire websites
- Website scrapers that grab the content of websites and re-use it without permission on automatically generated doorway pages
- Viruses and worms
- DDoS attacks
- Botnets, zombie computers, etc.
However, not all bots are bad for you. Many are of huge benefit to your site, such as search engine bots, without which Google may not have become the monster it is. Being listed in search results is a positive thing, so blocking those bots is a definite no-no.
The first such instance was WebCrawler, first put to work in 1995 by AOL (and then Excite two years later). Googlebot, the most famous of them all, was created in 1996, and went on to become the most sought after visitor to websites seeking organic, “free” traffic.
The first signs of bots being used at scale in a somewhat commercially-shady sense occurred, predictably, as the internet entered our homes. The 1990’s saw an explosion in connectivity, and the late 2000’s witnessed the smartphone boom, giving bots even more room to grow into.
If there’s easy money to be made, you can guarantee some humans will find a way to take advantage, and the rise in bots is no different. Hubspot provide a good breakdown of the most common types of good/bad bots here.
The Google Analytics solution
Right out of the box, Google Analytics allows you tick a box to “Exclude all hits from known bots and spiders”.
Great – but this only excludes known bots from reports, and can’t spot new bots, or indeed those that don’t behave in a manner typical to how Google trigger this filter.
So how do you spot a bot?
The most common fingerprint of a bot visit (within Google Analytics) is very low quality traffic – indicated by 100% New Sessions, 100% Bounce Rate, 1.00 Pages/Session, 00.00.00 Avg Session Duration, or all of the above.
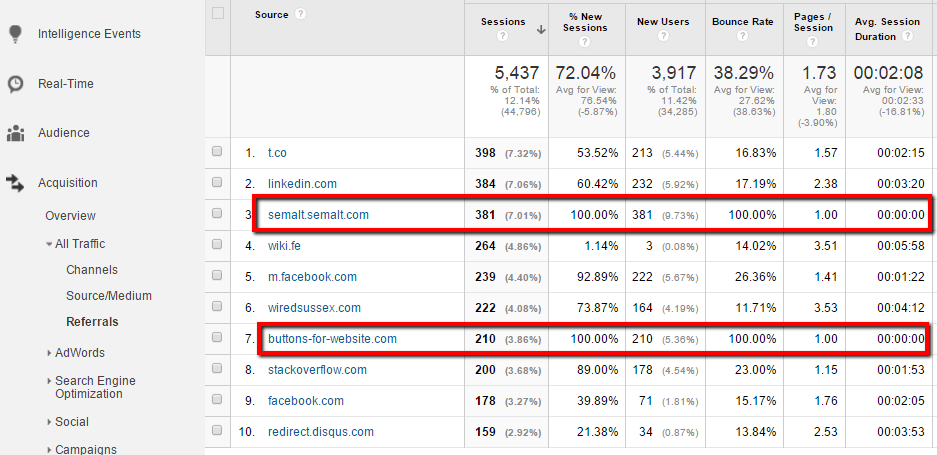
Monitoring referrers within Google Analytics can help you identify domains sending such poor traffic, which you can then exclude from your reports (Screenshot above courtesy of Freshegg.co.uk, who also provide a decent guide on how to deal with GA filters).
However, this option will not stop bots from accessing your site and content, meaning your infrastructure costs increase with zero benefit to you or your company, and possibly a negative effect should they be of the really-naughty variety.
Ghost Traffic Spam
Let’s look at how to exclude “ghost spam”, traffic that uses the Google API to inject spam data without actually visiting your website. This is achieved by abusing the GA Measurement Protocol, the system allowing developers to make HTTP requests to send user interaction data straight to the GA servers.
While this phenomenon is rarely a danger to your site or your visitors, it can muddy your reporting. It’s also worth pointing out why it exists, as there seems to be very little incentive for an unknown third party to inflate your Analytics statistics.
The referrer or referral spam is a fake URL sent to Google analytics in order to attract people to that URL and promote their service or product, and in some cases, to inject malware by asking you to insert a code in your site.
It seems a long shot from the spammer’s angle, and it is, but the volume at which fake referrals can be generated makes it a slightly more attractive, scalable target. In most cases, random Google Analytics tracking IDs are targeted by automated software. It’s a blunt technique, but can be annoying to anyone who gives their GA account more than a weekly glance.

Hostname Filters
The most labour-efficient way to prevent such traffic by ruining your day is by creating a valid hostname filter. This will exclude any session/visit where the destination URL was not a property using your GA ID.
AS the hostname is where your legitimate visits arrive, it’s important to include all your properties which are sharing this ID.
To implement this filter in GA, first navigate to Audience -> Technology -> Network, and change the dimension to Hostnames.
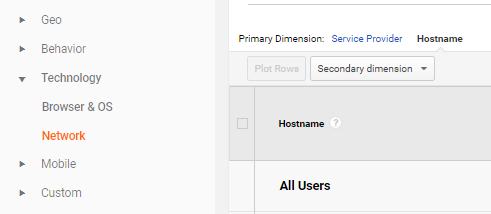
From here, list all the hostnames you recognise as real and worthy of inclusion in your overall analytics.
Next, you create the hostname expression, using the pipe character to separate each entry. For example, a filter list could look something like:
mobiforge.com|subdomain.mobiforge.com||anothersubdomain.mobiforge.com|mobiforge.com.googleweblight.com|translate.googleusercontent.com|youtube.com
If your site(s) warrant a more flexible solution, you can simplify by including just the words that’ll trigger the inclusion, or even create REGEX filters. (For more information on this stage, check out Carloseo.com’s Hostname Filter guide.)
mobiforge|googleweblight|googleusercontent|youtube
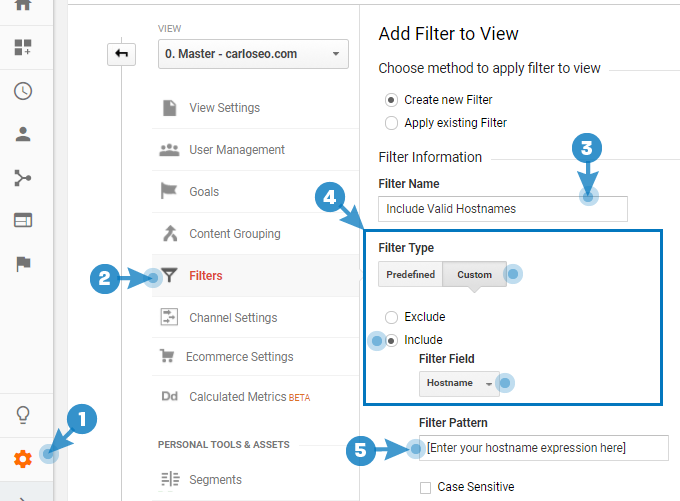
Now you have your list, it’s easy to add it to your GA account. Head to your Admin panel (1), and navigate to the Filters section (2). Here, you need to Create new Filter, ensuring you select Custom filter type (4), Include (or things could go really bad….) and finally Hostname as the filter field. (see image below).
Filter Pattern (5) is where you paste your list of hostnames, whether in REGEX form or simplified domain list. Click Verify this filter, and then Save.
Cutting the bot problem at source
Now that you’ve managed to exclude most known malicious bots and crawlers from your Analytics reports, as well as restricting the included hostnames, the next step is to look at streamlining your server by stopping them before they get to waste your precious resources.
It’s possible to prevent bots accessing your site using a few different methods, such as using Robots.txt, your htaccess file, or adding custom meta-tag directives to your site (or specific pages). However, to do this effectively, and avoid inadvertently blocking helpful bots from your site, patience and meticulous attention to detail is required.
There’s also the possibility that the nasty bot will simply ignore your instructions.
Wouldn’t it be great if you could employ a bouncer, of sorts, to stop visitors before they enter, checking their credentials before allowing them beyond the velvet rope? No need to waste resources, bandwidth and effort on visitors that aren’t bringing any value, and could even cause trouble for your regular patrons.
This way, only real visitors and helpful, worthy non-humans will get to see your site.
Employing a dedicated bot detection solution can take the strain off you and your team, by handling all aspects in real-time. With an accurate database of known and new bots, and the ability to allow the good ones through, it’s definitely something worth considering.




Leave a Reply